
在上一篇中,我们见证了 CTC 如何用一个空白符和一条序列级损失函数,拆掉了 HMM 的三道墙。它是端到端的第一次冲击:音频进去,文字出来,不需要任何对齐标注。
但 CTC 留下了一道裂缝:
它告诉模型"生成什么文字",却没有告诉模型"应该在哪里听,以及上下文是什么"。
每一帧的输出都独立计算,语言的规律被完全忽略。识别"再"还是"在",CTC 无能为力。
于是在 2012 到 2016 年间,两种不同的解决思路几乎同时出现——但它们来自完全不同的研究血统,解决问题的哲学截然相反。
这两种思路,就是 RNN-T(RNN Transducer) 和 AED(Attention-based Encoder-Decoder)。
一、先说结论:两条血统,两种哲学
ASR 的端到端时代,存在两条几乎独立演化的血统:
① 语音识别传统派:HMM → CTC → RNN-T
② NLP/翻译外来派:Seq2Seq MT → Attention → AED/LAS
| 语音传统派 | NLP 外来派 | |
|---|---|---|
| 代表 | CTC / RNN-T | AED / LAS |
| 起源 | 语音识别社区 | 机器翻译社区 |
| 核心问题 | 如何处理时间对齐 | 如何建模序列关系 |
| 对齐方式 | 显式概率路径求和 | Attention 自动学习 |
| 时间约束 | 强(单调) | 弱(可回看) |
下图展示了这两条血统的完整演化路径,以及它们最终如何在现代框架中合流:
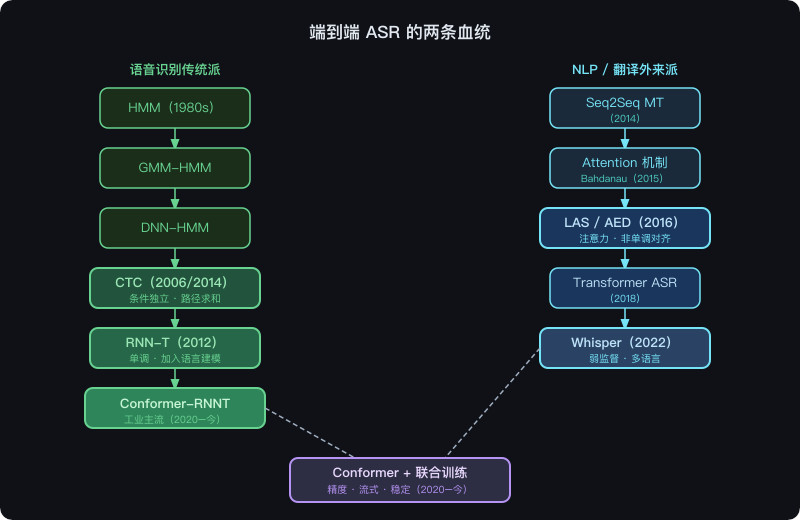
理解了这个分野,后面所有的设计选择都会变得自然。
二、CTC 的裂缝:独立假设的代价
要理解两种方案为何都被需要,必须先直视 CTC 的局限。
局限一:条件独立,把句子切成了碎片
CTC 的核心假设是:每一帧的输出,只依赖于输入音频,与已生成的文字无关。
$P(\text{路径} \mid X) = \prod_{t=1}^{T} P(y_t \mid X)$
生成第 10 个字时,模型对前 9 个字一无所知。"我在北京"和"我再北京",对 CTC 而言音频几乎一样,难以区分。语言的规律——"他吃了一个___"后面大概率是食物——CTC 完全不知道。
局限二:单调对齐,不能回头
CTC 还有一个隐形约束:输出必须与输入保持单调的时间顺序。你不能让模型先"听"第 30 帧,再回到第 5 帧做判断。但真实语音中,重音、停顿、语调都在影响词义理解——语音是动态的、非线性的。
CTC 是一条单行道,走了就不能回头。
两条路由此分叉:
- RNN-T 的选择:保留单调性,但修复独立假设——在对齐框架内引入语言建模能力;
- AED 的选择:打破单调性,彻底重新设计——用注意力机制让模型自由决定"听哪里"。
三、RNN-T:CTC 的正统传承
RNN-T = CTC 的推广
RNN-T(RNN Transducer)由 Alex Graves 于 2012 年提出,比 AED 早了整整 4 年。它不是对 CTC 的反叛,而是对 CTC 的直接延伸。
CTC 最大的问题是条件独立假设,那么最直接的修复方案是:在预测时加入输出历史。
CTC 建模的是:
$P(y_t \mid X)$
RNN-T 建模的是:
$P(y_{t,u} \mid X, y_{<u})$
多了 ${<u}$,也就是"已经生成的文字"。这一小步,在数学上意味着巨大的改变——模型终于能利用语言的统计规律了。
从数学上可以严格证明:当 RNN-T 的预测网络退化为常数时,RNN-T 就退化为 CTC。
CTC 是 RNN-T 的特例。
RNN-T 的结构:三个网络的协作
Encoder(转录网络):与 CTC 完全相同,将音频帧编码为高维声学表示。
Prediction Network(预测网络):本质上是一个神经语言模型,以已生成的 token 序列为输入,输出语言上下文状态。
Joint Network(联合网络):将声学状态与语言状态融合,预测当前步骤应该输出哪个 token(或 blank)。
一个容易误导人的名字
RNN-T 的全称是 RNN Transducer,"RNN"来自原始论文的标题——Sequence Transduction with Recurrent Neural Networks。Graves 2012 年的原始实现中,Encoder 和 Prediction Network 都用普通 RNN(tanh/sigmoid 激活)构建。
但这个名字此后经历了两轮"名不副实"的演化:
第一轮:RNN → LSTM。 工业界落地时,普通 RNN 被替换为 LSTM(RNN 的主流变体),训练更稳定,长程依赖建模更强。这个阶段"RNN-T"这个名字还算名副其实,毕竟 LSTM 仍是 RNN 的一种。
第二轮:LSTM 也被替换掉了。
- Encoder 的 LSTM 先被 Transformer 取代,最终被 Conformer 取代——也就是今天的主流;
- Prediction Network 的 LSTM 则被研究发现其实不必要。ASR 不像翻译,预测当前字几乎只需要看前 1–2 个 token,LSTM 的长程记忆在这里没有用武之地。于是工业界用无状态的 Embedding 查表(stateless predictor)替代,速度更快,WER 几乎没有损失。
结果就是:今天工业界跑的"RNN-T",Encoder 是 Conformer,Prediction Network 是 Embedding 查表,Joint Network 从来就只是一个全连接层。
名字里的 RNN 早已名存实亡——留下来的只是那套单调对齐的数学框架。
RNN-T 的对齐:在二维格上的游走
RNN-T 的对齐可以用一个二维格来理解。横轴是时间帧 $,纵轴是已输出 token 数 $。每一步,模型只有两种选择:
- 向右(emit blank):推进时间,继续听下一帧;
- 向上(emit token):输出一个字符,停在当前时间帧。
这个约束保证了时间永远单调增加——模型永远不会回头,天然支持流式。
| 操作 | 含义 |
|---|---|
| 输出 blank | 时间前进,t → t+1 |
| 输出 token | 文本前进,u → u+1 |
| 不允许 | 回到过去时间 |
类比:你一边听录音,一边用铅笔跟着写字。笔可以停下来等,但磁带不能倒带。
下图展示了 RNN-T 在二维格上的一条具体路径——蓝色节点代表输出 token,绿色箭头代表 blank(时间前进):

四、AED:NLP 的外来入侵
来自另一个世界的思路
2014 年,Sutskever 等人用 Seq2Seq 框架征服了机器翻译;2015 年,Bahdanau 引入注意力机制,让翻译模型能够动态聚焦源语言的不同位置。
2016 年,Google Brain 的 Chan 等人提出了一个大胆的想法:
把翻译模型直接搬到语音上。
这就是 LAS(Listen, Attend and Spell)——AED 架构在 ASR 领域的第一个成功实例。LAS 的名字本身就是架构说明书:
| 模块 | 职责 |
|---|---|
| Listen(Encoder) | 将音频特征编码为高维表示 |
| Attend(Attention) | 动态聚焦相关音频帧 |
| Spell(Decoder) | 自回归逐字生成文本 |
注意力机制:给模型装上"耳朵的焦点"
注意力机制的直觉类比:
当你誊写一段录音时,你不会每写一个字母都重新扫描整段音频——你会自然地把注意力集中在当前字对应的那段声音上,然后移向下一段。
关键突破:模型不再被迫按时间顺序生成——它可以自由决定,生成这个字时该聚焦哪段声音。单调约束被打破了。
Decoder:用语言的逻辑生成文字
AED 的 Decoder 是一个自回归 RNN(或 Transformer),每次生成一个字符,并将其作为下一步的输入:
$P(y_i \mid y_{<i}, X) = ext{Decoder}(s_i, c_i, y_{i-1})$
生成"京"时,模型已经知道前面是"北",语言的逻辑被显式编码进了解码过程。
与 CTC/RNN-T 的本质区别:
CTC/RNN-T 是"路径求和"——对所有合法的对齐方式积分;
AED 是"注意力对齐"——让模型自己学习应该在哪里看。
五、核心对比:相同的 Encoder,截然不同的上层
这是 AED 与 RNN-T 最容易被忽视的事实:
两者的 Encoder 可以完全一样。
现实中,Conformer Encoder 既可以接 AED 的注意力 Decoder,也可以接 RNN-T 的 Joint Network。区别完全发生在 Encoder 之后,如下图所示:

| 维度 | AED | RNN-T |
|---|---|---|
| 对齐方式 | Attention(软对齐,可跳跃) | 二维格游走(单调) |
| 语言建模 | Decoder 自回归 | Prediction Network |
| 流式支持 | 困难(需看完整段) | 天然支持 |
| 推理延迟 | 高 | 低 |
| 识别精度 | 通常更高 | 略低,但差距在缩小 |
| 训练难度 | 相对容易 | 梯度路径数量指数级,较难稳定 |
| 典型用途 | 离线转写、多语言 | 语音助手、实时字幕 |
为什么 AED 不能流式?
AED 的 Encoder 通常是双向的——它需要同时看到前后的帧;Decoder 的注意力需要在整段音频上计算权重。
结果:你说完整句话,系统才开始生成第一个字。
在实时语音助手场景,这是致命的。
为什么 RNN-T 能流式?
RNN-T 的二维格结构从数学上保证了时间单调——每一步要么推进时间,要么输出 token,永远不会回头看。这使得只要接收到新的音频帧,就可以立即运算,延迟极低。
Conformer:两者共享的最强 Encoder
Conformer 的核心思路是:
Transformer 擅长全局依赖,CNN 擅长局部声学特征——把两者结合。
每个 Conformer Block 按顺序包含四个子模块:
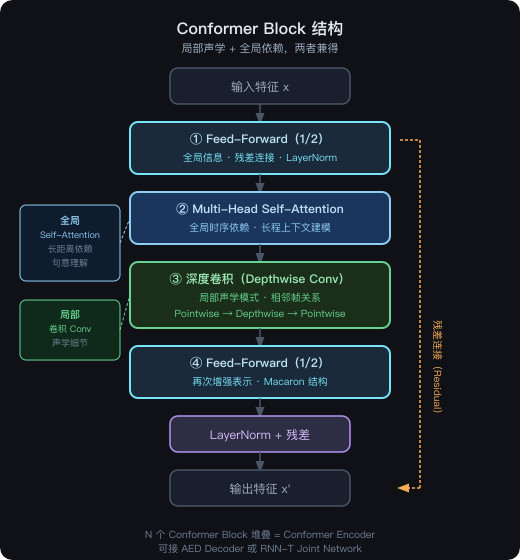
- Feed-Forward(1/2):全局信息混合,Macaron 结构的第一半;
- Multi-Head Self-Attention:建模全局时序依赖,捕捉长程上下文;
- 深度卷积(Depthwise Conv):捕捉局部声学模式,处理相邻帧关系;
- Feed-Forward(1/2):再次增强表示,Macaron 结构的第二半。
N 个 Conformer Block 堆叠,就构成了完整的 Conformer Encoder。它既可以接 AED 的 Attention Decoder,也可以接 RNN-T 的 Joint Network——这正是现代 ASR 系统的标配组合。
效果有多显著?2020 年 Google 发表 Conformer 论文时,仅用 30.7M 参数就超越了此前使用 139M 参数的 Transformer Transducer,在 LibriSpeech 测试集上不加语言模型达到 2.1%/4.3% WER,加入外部语言模型后进一步降至 1.9%/3.9%。参数量不到四分之一,精度反而更高——这正说明瓶颈从来不在解码器的设计,而在 Encoder 能否同时抓住局部声学和全局语义。
六、历史的戏剧性:谁先出现不一定代表谁先实用
RNN-T 于 2012 年提出,比 LAS/AED 早了整整 4 年。但在相当长的时间内,学界的目光反而集中在 AED 上。
原因是工程现实:
RNN-T 在 2012 年几乎跑不动。
- Joint Network 需要计算 T×U 的二维对齐格,显存占用极大;
- 梯度需要在指数级的路径数量上反向传播,训练极不稳定;
- 当时的 GPU 根本无法支撑大 batch 训练。
而 AED 在 2016 年出现时:
- Attention 机制训练友好,loss 直观;
- GPU 集群已足够强大;
- 在 WER 上迅速超越了当时的 CTC 系统。
于是从 2016 到 2019 年,AED 看起来要统一端到端 ASR。
然后,Google Assistant、Siri、Alexa 的实时需求撞上了 AED 的流式缺陷。工业界重新翻出了 RNN-T,这次 TPU 已经就位,Conformer Encoder 也已成熟:
RNN-T 在沉寂 7 年后,于 2019–2020 年间统治了工业界。
七、代表模型:两条路各自的演化
AED 家族
| 模型 | 时间 | 核心改进 |
|---|---|---|
| LAS | 2016 | pBLSTM + 内容注意力,开山之作 |
| Transformer ASR | 2018 | Encoder/Decoder 全替换为 Transformer |
| Conformer-AED | 2020 | Conformer Encoder,精度达到新高 |
| Whisper | 2022 | 68 万小时弱监督数据,zero-shot 多语言 |
| SenseVoice | 2024 | 非自回归 Decoder,推理速度极快;严格来说已超出传统 AED 范畴,但仍属 Encoder-Decoder 框架 |
RNN-T 家族
| 模型 | 时间 | 核心改进 |
|---|---|---|
| RNN-T | 2012 | 原始论文,LSTM Encoder + LSTM Predictor |
| LSTM-RNNT | 2019 | Google 在语音助手中大规模落地 |
| Conformer-RNNT | 2020 | Conformer 替换 LSTM Encoder,精度大幅提升 |
| Streaming Conformer | 2021 | Chunk-wise attention,实现低延迟流式 |
八、现代工业的选择:互补而非对立
工业界的标准答案是:
Conformer-RNNT 做实时流式识别 + AED Rescore 做精度提升。
这也是 ESPnet、WeNet 等主流框架的默认配置:CTC 辅助训练稳定收敛,AED 提供语言建模能力,推理时 CTC/RNNT 初筛候选,AED 精排最终结果。三者不是竞争关系,而是分工协作。
两条血统在 2020 年代终于开始合流。
附录:为什么 RNN-T 的训练比 AED 难稳定得多?
这是很多论文不会直接点明的一个工程事实。
梯度路径数量的差异
AED 的训练目标相对直接:最大化 P(Y|X),Decoder 每步的梯度沿着明确的路径传播。
RNN-T 的情况完全不同。它需要对所有合法的对齐路径求和:
$P(Y \mid X) = \sum_{ ext{所有合法路径}} P( ext{路径} \mid X)$
对于长度为 T 的音频和长度为 U 的文本,合法路径的数量是 C(T+U, U),呈指数级增长。虽然 forward-backward 动态规划将计算复杂度降到了 O(T×U),但梯度传播仍然需要在这张 T×U 的对齐格上流动,显存占用巨大,梯度容易爆炸或消失。
工程解决方案
现代训练中通常采用以下策略应对:
- 梯度裁剪:防止梯度爆炸;
- CTC 联合训练:CTC loss 提供稳定的初始梯度信号,帮助模型在训练早期找到合理的对齐;
- 分块训练(Chunked RNNT):将长音频切块,减少 T×U 矩阵的尺寸。
这也解释了为什么 RNN-T 在 2012 年提出后沉寂了 7 年——不是思想有问题,而是工程条件不成熟。
标题:ASR概念和术语学习指南(4):CTC之后的两条道路——AED 与 RNN-T
作者:aopstudio
地址:https://www.neusoftware.top/articles/2026/02/27/1772194264113.html